Business

Business
The overall objectives are to 1) develop and implement improved multi-scale automatic history-matching technology to integrate production and time-lapse seismic data with a geologic model to obtain high resolution reservoir models, and 2) implement these methods in public domain software that can be used as a reservoir management tool by small oil companies.
University of Tulsa, Tulsa, OK
University of Oklahoma, Norman OK
Despite longstanding interest in the oil and gas industry, automatic history-matching has seldom been used in practice due to obstacles related to computational efficiency. Because of this, manual history-matching has been the norm, and as a consequence, reservoir engineers have frequently made changes to reservoir simulation models that resulted in a history-matched reservoir model inconsistent with static data and geologic information and interpretation. Thus the model obtained by history-matching often gave unreliable predictions of future reservoir performance.
When implemented into the software, the algorithms and technology developed in this research project will provide a platform for data integration with the history-matching process in order to obtain a history-matched reservoir model that is consistent with all data and information. This will result in better predictions of future production and quantification of uncertainty in predicted reservoir performance and lead to improvements in reservoir management. More importantly, these algorithms will be embedded into software with easy to use GUIs and be available to smaller companies that normally would not have access to reservoir simulation/automatic history-matching tools.
Results
To date, the following milestones have been accomplished:
Benefits
This project will advance the reservoir modeling and reservoir management capabilities of the petroleum industry by providing a practical tool in the form of user-friendly software for data integration, reservoir simulation, and automatic history-matching. Students trained with support from this project will be prepared for employment in the oil industry and bring with them expertise in advanced tools for reservoir management.
Summary
The seven tasks delineated in the original proposal were:
Task 1 – Development of an algorithm for history-matching with facies; Task 2: Automatic history-matching of time-lapse seismic data; Task 3: Determination of the relative weighting of data mismatch terms; Task 4: Adjustment of relative permeability curves by history-matching; Task 5: Multi-scale history-matching; Task 6: Graphical user interface user manual; and Task 7: Examples applications.
Task 1 – History-matching of facies boundaries using gradient-based methods was found to be relatively inefficient. Consequently, the researchers began work on history-matching with facies using the ensemble Kalman filter. The method has been developed and implemented in code for three-dimensional problems. Initial tests on using the method to adjust facies boundaries by matching production data have been successful, but the problems tested were relatively simple and much research remains to be done.
Task 2 – A methodology and code for the automatic history-matching of time-lapse seismic data have been completed. This methodology has been embedded in the overall code so that one can simultaneously match time-lapse seismic and production data.
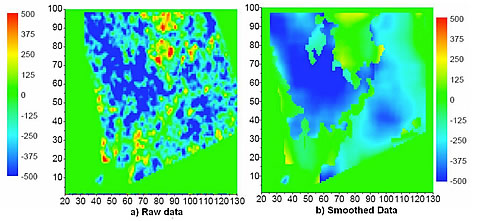
Task 3 – Researchers have developed methods to determine the relative weighting of data mismatch terms. To integrate dynamic data into a geologic model by automatic history-matching, it is important to determine the proper relative weighting of data in the objective function that is minimized. The relative weighting is determined by the covariance functions describing measurement errors. For estimation of the covariance functions for different types of production data, the team’s implementation of Savitzky-Golay filters and soft-threshold de-noising using the wavelet transform both yield reasonable estimates of covariance functions, but results are less accurate when the errors are correlated or non-stationary. A modified EM algorithm was implemented to characterize measurement error in time-lapse seismic and production data. Extensive testing indicates that the modified EM algorithm gives reliable results for determining the covariance functions for production data (pressure, producing water-oil and gas-oil ratios) as well as time-lapse seismic data. The modified algorithm groups data by value and coordinates and automatically determines the number of groups. By smoothing within groups, the project performer is able to obtain a reliable characterization of measurement errors. Researchers have also developed a modification that allows them to consider two data types together, e.g., acoustic impedance and Poisson’s ratio. This modification results in a more reliable grouping. Preliminary tests on synthetic data indicate that the modified EM algorithm can be applied to separate porosity and permeability measurements by rock type.
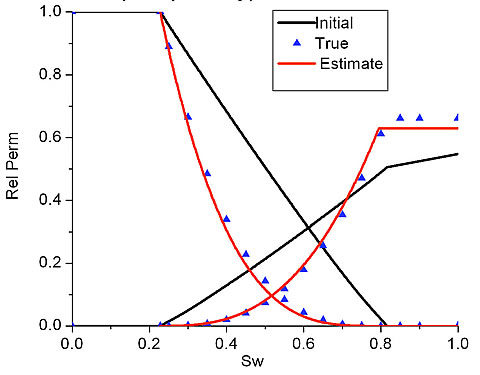
Task 4 – Code for estimating relative permeability curves, together with gridblock porosities and absolute permeabilities, has been completed and successfully tested with several synthetic examples. Tests indicate that, in many cases, production data will not be sufficient for accurate estimation of the control points in a B-spline parameterization of relative permeability curves, so this representation should be used with caution. Estimation based on power law models for relative permeability curves is more robust.
Task 5 – Essentially no work has yet been done on multi-scale history-matching because the student who was scheduled to work on this project was engaged in the development of the EM algorithm. The discovery of this promising algorithm was unexpected when the project was initiated. The intent was to work on Task 5 during the final year of the project, but because Federal funding was not provided for the third year of the project, this task has been deleted.
Task 6 – A GUI was developed. The GUI can be used to run the CLASS reservoir simulator and to estimate permeability and porosity fields and parameters describing relative permeability curves by the automatic history-matching of production data and time-lapse acoustic impedance data. Final testing of the code is underway. This code is publicly available on the TUPREP website, http://www.tuprep.utulsa.edu [external site].
Task 7 – Several synthetic cases related to history-matching production and seismic data have been done. A field case on integrating time lapse seismic data has also been completed. This history-matching software has been compared with the ensemble Kalman filter for the PUNQ-S3 problem; both methods gave similar results in terms of the estimates of permeability and porosity fields obtained and the quantification of uncertainty in predicted reservoir performance. The EM algorithm has been applied to field cases to estimate measurement errors in both time-lapse seismic data and production data.
(February 2008)
The project began on October 1, 2004. Except for additional testing of the code, Tasks 2, 3, 4 and 7 are complete. As noted above, Task 5 has been deleted. During a 6-month, no-cost extension, the project performer has been focusing efforts on refining and testing the Graphic User Interface (Task 6), investigating further reservoir applications of the EM algorithm, and doing additional work on using the ensemble Kalman filter to adjust facies boundary (Task 1).
Funding
This project was selected in response to DOE’s Oil Exploration and Production solicitation DE-PS26-04NT15450-2C, February 10, 2004.
$797,909
$215,312 (21 percent of total)
NETL – Traci Rodosta (Traci.Rodosta@netl.doe.gov or 304-285-1345)
TU - Al Reynolds (reynolds@utulsa.edu or 918-631-3043)
Publications
Ning Liu and D.S. Oliver, “Critical Evaluation of the Ensemble Kalman Filter on History Matching of Geologic Facies,” SPE Reservoir Evaluation and Engineering, 8(6), pp. 470-477, 2005.
Yannong Dong and D.S. Oliver, “Quantitative Use of 4-D Seismic Data for Reservoir Description,” SPE Journal, 10(1), pp. 51-65, 2005.
Yong Zhao, Gaoming Li, and A.C. Reynolds, “Characterization of the Measurement Errors in Time-Lapse Production Data with an EM Algorithm,” presented at the IFP Quantitative Methods for Reservoir Characterization, sponsored by the French Academy of Sciences, April 2006, Rueil-Malmaison, France, to appear in Oil & Gas Science and Technology.
Yong Zhao, Gaoming Li, and A.C. Reynolds, “Characterizing Data Measurement Errors with the EM Algorithm,” Proceedings of the Tenth European Conf. on the Mathematics of Oil Recovery, September 2006, Amsterdam, the Netherlands.
Mohammad Zafari, Gaoming Li, and A.C. Reynolds, “Iterative Forms of the Ensemble Kalman Filter,” Proceedings of the Tenth European Conf. on the Mathematics of Oil Recovery, September 2006, Amsterdam, the Netherlands.
Guohua Gao, Mohammad Zafari, and A.C. Reynolds, “Quantifying Uncertainty for the PUNQ-S3 Problem in a Bayesian Setting with RML and EnKF,” SPE Journal, 11(4), pp. 506-515.